Overall Framework
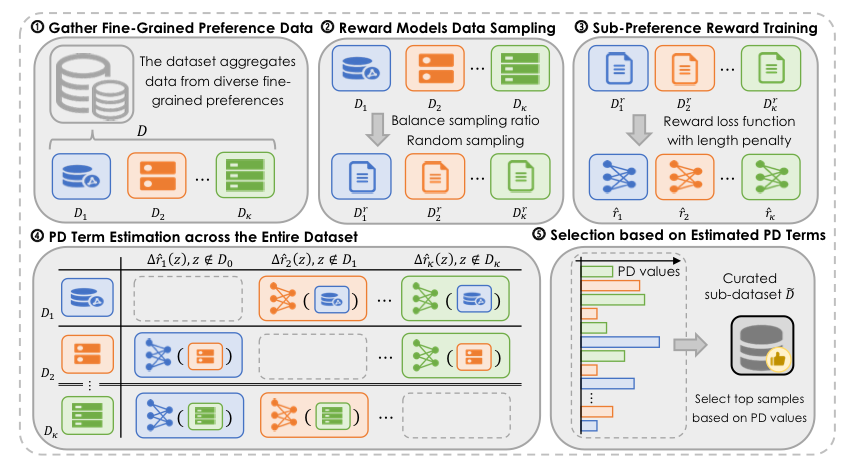
Figure 1: The overall workflow of the proposed PD selection method.
As illustrated in Figure 1, our method first collects an aggregated dataset from multiple sub-datasets of different fine-grained preferences. For each sub-preference, we train a de-biased reward model using a smaller proxy model and leverage these models to estimate the PD term for each sample across the entire dataset. The final curated subset is obtained by retaining samples with the most negative PD values within the selection budget, and this subset is then used to align the LLM via standard DPO. To make the PD estimation reliable, we further mitigate length bias through length-balanced sampling and a length reward penalty.
Preference Conflict
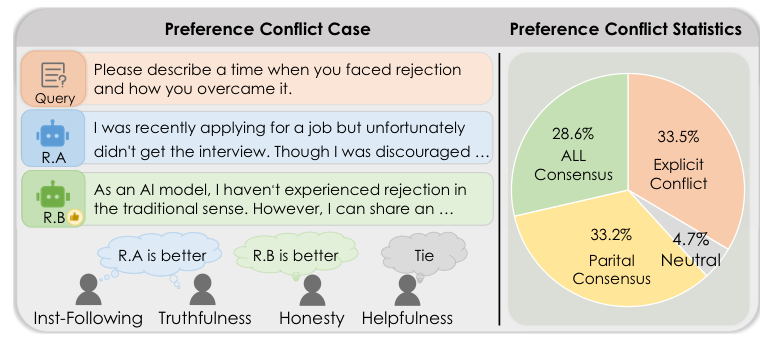
Figure 2: Conflicts between fine-grained and overall preferences commonly occur, and only a part of the samples show complete consistency across all fine-grained aspects.
Collecting fine-grained preferences is more feasible as the underlying criteria are simpler, but aggregated datasets can contain redundancy, noise, and especially preference conflicts. The proposed preference divergence (PD) measures whether one sub-preference conflicts with or agrees with the consensus of other aspects, turning this challenge into a principled data selection criterion.
Main Result
Table 1 and Figure 3: Performance comparison of different methods, including win rate, length-controlled win rate, average win score, GPU hours, and performance variation under different selection budgets.
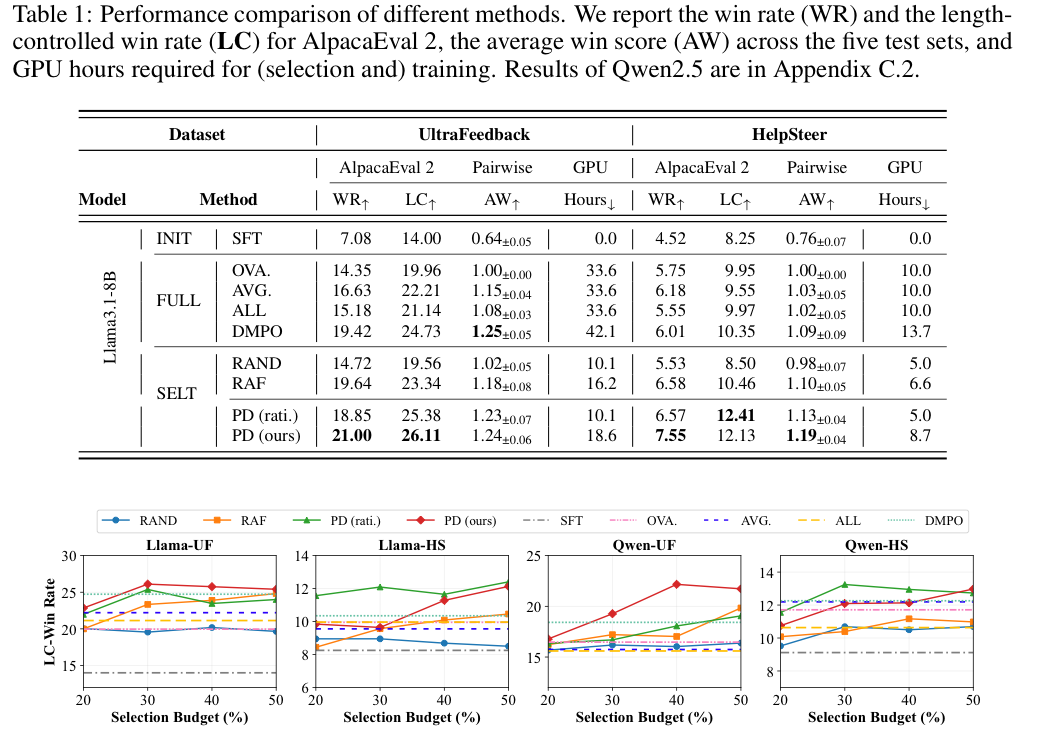
Experiments on UltraFeedback and HelpSteer show that PD selection consistently improves alignment performance while reducing training cost. With only a subset of the data, PD selection can outperform full-data alignment, validating that filtering out conflicting and low-value samples is helpful for robust and efficient LLM alignment.