Overall Framework
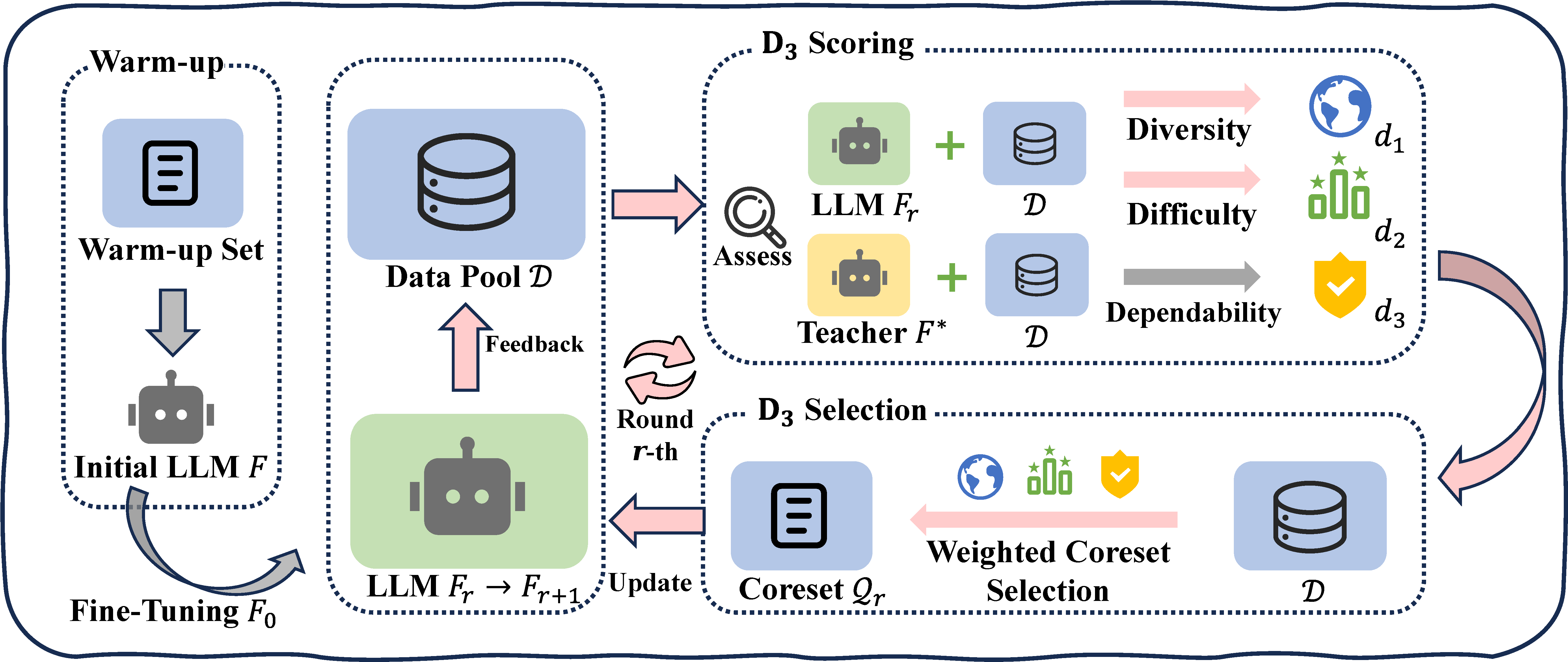
Figure 1: The overall framework of D3 data selection method, including the warm-up and two key steps of scoring and selection.
As illustrated in Figure 1, our method comprises a warm-up step and two key steps of scoring and selection. We first utilize a tiny portion of data to obtain the initially acclimated model \(F_0\). In the scoring step, we evaluate samples in \(\mathcal{D}\) across three criteria. Specifically, we define the diversity function to measure sample distinctiveness and introduce the uncertainty-based prediction difficulty (UPD) to assess sample difficulty by mitigating the interference of context-oriented generation diversity. Additionally, we incorporate a teacher LLM \(F^*\) to evaluate sample dependability. In the selection step, we formulate the D3 weighted coreset objective to solve for the most valuable subset for LLM tuning within the selection budget. We integrate the scoring and selection steps into an iterative process that leverages the feedback from LLM to enable the adaptive refinement of the selection focus over multiple rounds.
Main Result
Table 1: Performance comparisons of various data selection strategies across different datasets. The numbers in parentheses denote the sample sizes of test sets. Higher winning scores and leaderboard metrics indicate better performance, with the best results highlighted in bold.
